Software That Post-Trains Itself on Your Judgment
There's a quiet assumption baked into every piece of software ever sold: the product is fixed, and you are the variable. A vendor ships one generalized version of a workflow, watches aggregate usage, smooths the average path, and pushes an update that's a little better for everyone and therefore perfectly fitted to no one. Your feedback, if it goes anywhere, goes into a backlog. The software gets better at being generic. It never gets better at being yours.
That assumption is now inverting, and the inversion is bigger than "better software." The new artifact isn't a generalized flow a product team refines on your behalf. It's software you build — describing the workflow you already run in plain language, wiring it together on top of an SDK — that comes alive as a collaboration: the agents do the generation, and your people validate the output and fix what's wrong. Every fix is a signal. And because those agents are yours — dedicated to you, not shared across a thousand other companies — they compound on that signal until the work comes back the way you would have done it. Not "the UX got cleaner." The output got better at being the output you would have produced, because you were the one who defined what good means.
We already have a precedent for this. It's the exact thing that drove the biggest capability jumps in AI itself.
The jump was never just scale. It was feedback against a definition of "good."
When GPT-3 first appeared, it was a staggering next-word predictor that was also, out of the box, hard to actually use — it made things up, hedged, missed the instruction entirely. What turned that raw model into something useful wasn't a bigger model. It was RLHF: reinforcement learning from human feedback. Humans ranked competing outputs, those rankings trained a reward model — a learned stand-in for "what a person judges as good" — and the base model was then optimized against it.
The result made the point unmistakable. A 1.3-billion-parameter InstructGPT model produced outputs that human evaluators preferred over the 175-billion-parameter GPT-3 — more than 100× fewer parameters. OpenAI's own researchers put it bluntly: the feedback did more for the model's usefulness than a 100× increase in size would have. Teaching a system what you count as a good answer beat making the system bigger. The leverage was in the feedback, not the horsepower.

The next jump sharpened it. The o1 reasoning models didn't get good at hard math and code by absorbing more text. Through reinforcement learning, o1 learned to hone its chain of thought, catch and correct its own mistakes, break tricky steps into simpler ones, and try a different approach when the current one wasn't working. And the cleanest version of that gain came from verifiable reward — objective, grounded signals, like a test the answer either passes or fails.
Read the two leaps together and a pattern falls out. A capable base model improves dramatically not by getting bigger, but by being pointed at a clear definition of a good output — and then being allowed to try again against it. RLHF's signal was human preference. o1's was a verifiable check. In both cases, the definition of "good" was the thing that drove the jump.
That is exactly the lever now being put in the hands of the people who use software, not just the people who train models.
The new shape: you build it, the agents run it, your people judge it
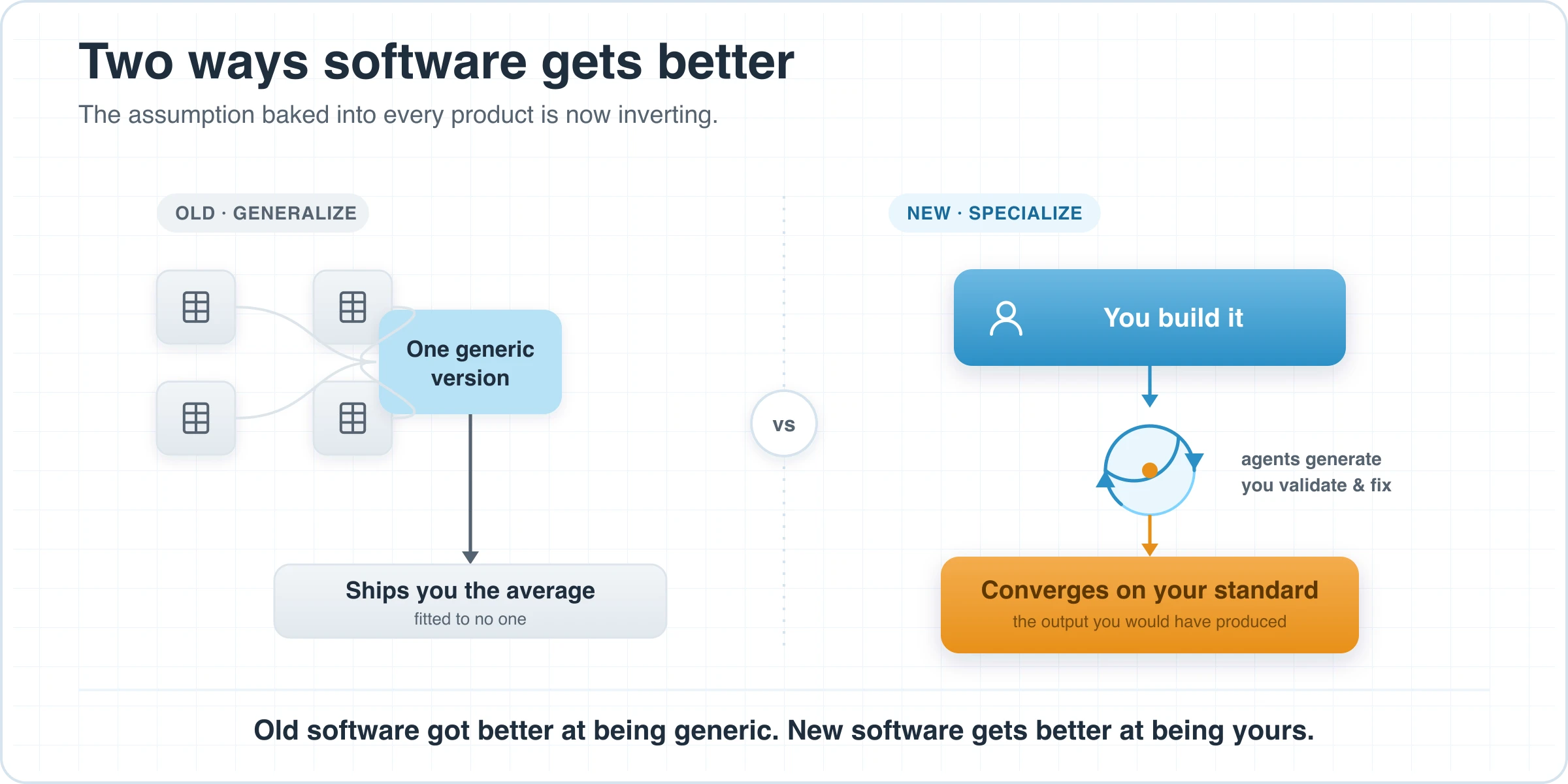
Here's the reframe. For decades, "software improving" meant a vendor generalizing across all customers and shipping you the average. The new model is local, and it has three moves.
You build the software. Not file a feature request and wait — you describe the job the way your shop actually does it and assemble it yourself, in plain language on top of an SDK. The software is your workflow, encoded, instead of someone else's workflow that you bend yourself around.
The agents do the work; your people judge it. The software runs as a collaboration. Dedicated agents generate the output — the draft estimate, the addendum review, the submittal package — and your people validate it and fix what's off. That validation step is not bureaucracy and it is not a pass/fail bouncer at the end of the line. It is the most valuable thing in the system, because it is the encoded statement of "this is what good means, here, for us." Your validation is the reward signal — your version of the human ranking in RLHF and the verifiable check in o1.
The agents learn your judgment. A fix isn't a one-time correction; it's a precise statement of what right looks like, far richer than a thumbs-up. Fed back consistently, your agents stop drifting toward the generic average and start converging on your standard. They post-train on your judgment. Month six is sharper than month one — not because a vendor shipped an update, but because you supplied a clean, repeated signal of what you were looking for, and the agents are yours to absorb it.
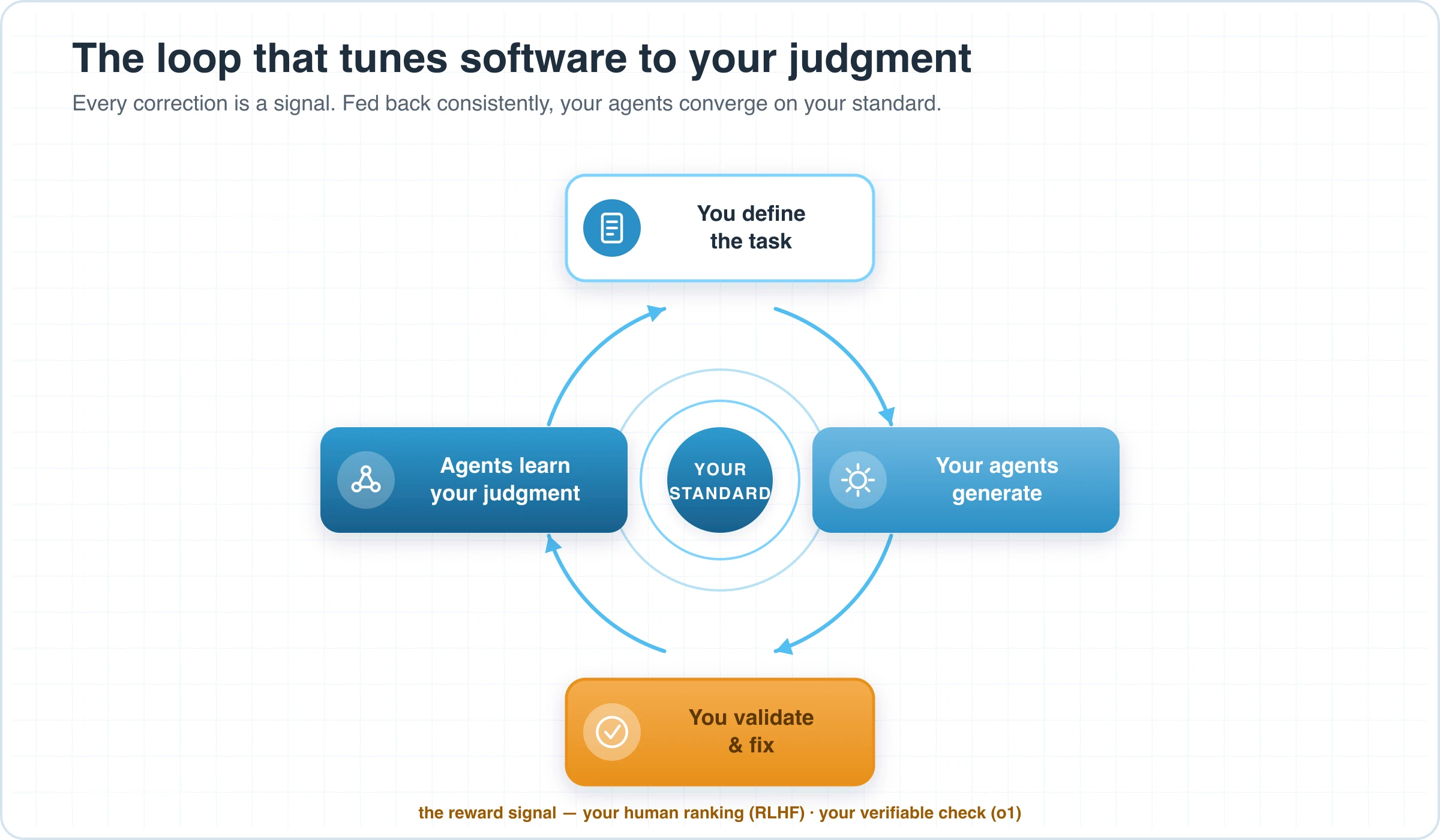
And because the target is narrow — your workflow, not the whole world — it doesn't take a research lab's worth of data to move it. A steady stream of real corrections on a well-defined task is enough.
The critical, slightly counterintuitive consequence: the ceiling on how good your software gets is set by the quality of your judgment, not by a vendor's roadmap. In RLHF, sloppy or inconsistent feedback produces a confused reward model and a worse result; clear, consistent preferences produce the leap. The same is now true of the software you operate. A vague standard teaches the system vague things. A sharp one — one that genuinely captures the judgment of your best people — is what lets the system actually try better and succeed. Judgment in, your judgment out, at scale.
Dedicated agents are what "you own your software" finally means
The piece that makes this real, and not just another configurable tool, is that the agents are dedicated. They are yours. The judgment your people pour into them trains them and only them — it is never pooled into a shared model that hands your hard-won standard to the company next door.
That's a deliberate bet, and it runs against the prevailing one. The dominant vision of AI is a single central super-model that ingests everyone's data and ships the average back — the same old generalize-and-flatten move, at a larger scale. The bet here is the opposite: the future isn't one model that knows a little about everything. It's every company running its own agents that know its work cold.
It works in two layers, and keeping them separate is the whole point. The craft layer — the raw capability of the underlying engine — is shared infrastructure; it gets better for everyone, and you inherit those gains without lifting a finger. The judgment layer — how your people decide what good looks like — stays local, private, and yours. You own the judgment; the platform improves the craft. Nobody mines the one to sell the other.
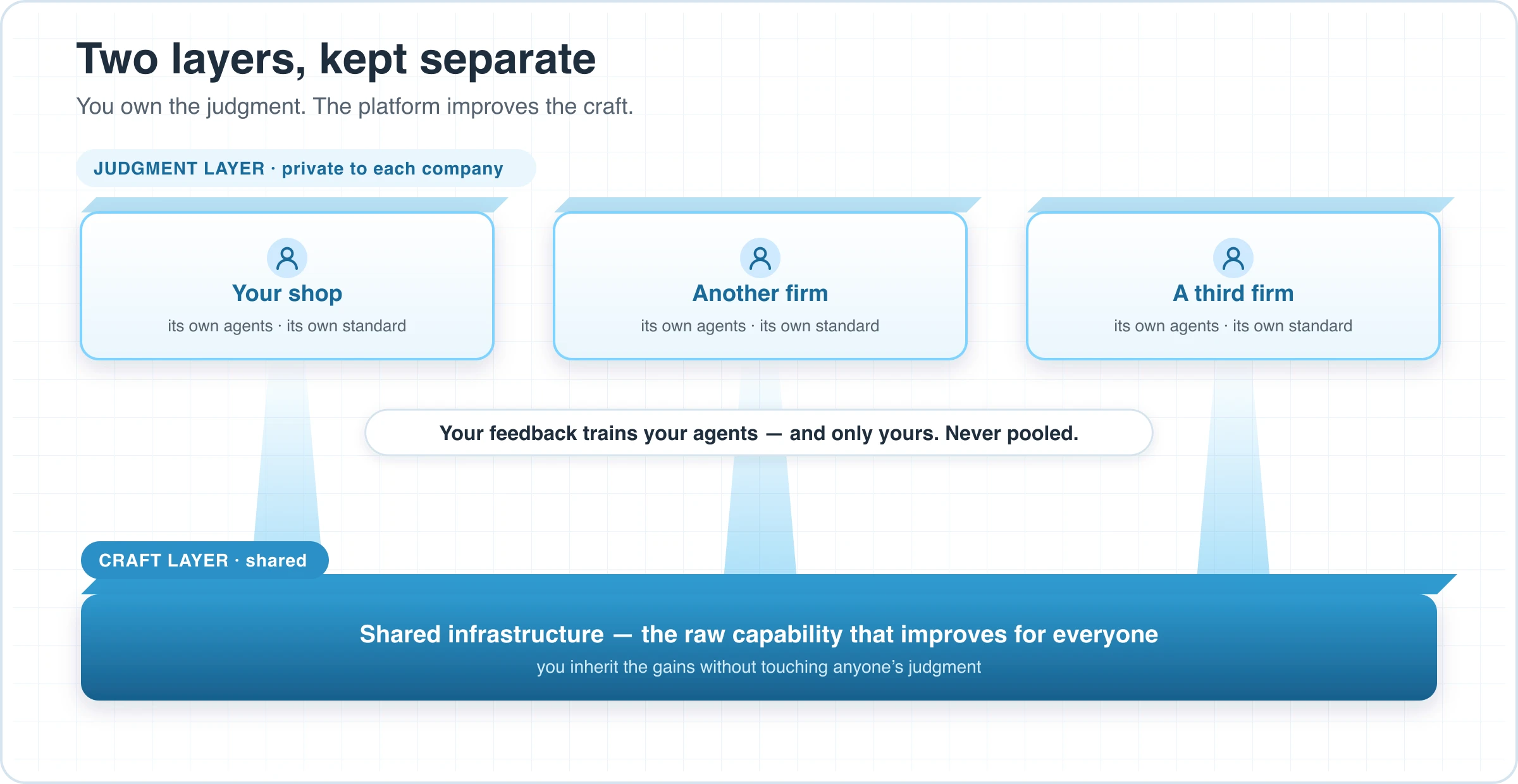
This is what "you own your software" was always supposed to mean. Not that you hold the source code, but that the thing improves along the axis you define, toward the standard you set, on the feedback you give — and that the value of that feedback accrues to you.
Why the trades make it concrete
It's easy to keep this abstract, so take an industry where the gap between generic software and real expertise has always been brutal: the trades. For years a contractor's only choices were enterprise software built for a generic version of someone else, or running the real work on spreadsheets and the knowledge in a few veterans' heads. The expertise that made a shop good — how a senior estimator reads a drawing set, what a sharp PM checks before a submittal goes out — was precisely the part no off-the-shelf product could hold. It lived in people, and it left when they left.
That is exactly what this captures. A contractor doesn't wait for a vendor to generalize "addendum review" across a thousand other companies and hand back the average. They build their review, the way their shop runs it. Their dedicated agents do the first pass. Their senior estimator validates it and fixes the misses — and every fix teaches the agents what a clean catch looks like here. The judgment that used to be unwritable becomes the thing the software runs on. And because a person stays in the validating seat, delegation never becomes abdication: the human remains the author of "good," even as more of the doing gets handed off.
Construction is a vivid case because the cost of generic software there was so visible. But the structure is universal. Any organization whose real advantage lives in how its people make judgment calls has, until now, been forced to either flatten that judgment into someone else's tool or keep it locked in human heads. For the first time there's a third option: build the software around the judgment, and let the judgment make the software better.
Workshop is where contractors build these dedicated agents, tuned to how their shop works →
The shift, in one line
Old software got better by generalizing across everyone and shipping you the average. New software gets better because you build it, your people judge its output, and your dedicated agents learn the specific standard you set — the same lever that turned a raw text predictor into something genuinely capable, now pointed at your work instead of the model's.
The model jumps of the last few years were never really about scale. They were about feedback against a clear definition of good. That lever is now yours. The only question left is the one that decides how far it carries you: how well can you define what good looks like?
Frequently asked questions
What does it mean for software to 'post-train' on your judgment?
It means you build software that models a workflow you already run, the system's agents generate the output, and your people validate it and fix what's wrong — and those corrections become the signal the software learns from. Over time your dedicated agents converge on your standard instead of drifting toward the generic average: month six is sharper than month one, not because a vendor shipped an update, but because you supplied a clean, repeated signal of what good means for your shop.
How is RLHF related to self-improving business software?
RLHF (reinforcement learning from human feedback) is the structure that turned raw models like GPT-3 into genuinely useful systems: humans ranked competing outputs, those rankings became a learned stand-in for 'what a person judges as good,' and the base model was optimized against it. The same structure now sits inside the software you operate. Your people validating an agent's output is the human-feedback signal; your dedicated agents are the thing that improves against it. You define what good means, here, for you — and the system learns it.
What determines how good self-tuning software can get?
The quality and consistency of your judgment, not a vendor's roadmap. In RLHF, sloppy or inconsistent feedback produces a confused result; clear, consistent preferences produce the leap. The same is now true of the software you operate. A vague standard teaches the system vague things. A sharp one — one that genuinely captures the judgment of your best people — is what lets the system actually try better and succeed.
Does my feedback improve a shared model that other companies benefit from?
No. The agents are dedicated to you. The judgment your people pour in trains your agents and only your agents — it is never pooled into a shared model that hands your hard-won standard to the company next door. Two layers stay separate: the raw capability of the underlying engine is shared infrastructure that improves for everyone, while how your people define good stays local, private, and yours. You own the judgment; the platform improves the craft.