Becoming an AI-Native Contractor: Own the Loop, or Rent Your Edge

Enterprises spent $30–40 billion on generative AI through 2025. MIT's NANDA initiative found 95% of it produced no measurable impact on the P&L. BCG, surveying more than 1,250 firms, reached the same place from another direction: 60% see no material value, and only 5% win at scale. Most AI spending buys activity, not advantage.
"AI-native contractor" is on every conference panel and vendor deck (and, fair enough, the headline of this site), and it has come to mean almost nothing. Here's what should worry you: the thing that makes your firm money — how your best estimator reads a spec, where he knows the scope hides, which clauses he won't sign — isn't in your software. It's in his head, and he's 61. When he retires, it walks out the door with him. Becoming AI-native is really one question: does that knowledge compound inside your firm, or leak out of it?
Here's the short answer. Becoming an AI-native contractor isn't a purchase, it's a structure: a closed loop run on your own data (data, policy, tools, QA, learning) where you own the one step that compounds — learning. Almost every product sold to contractors hands you a single piece of that loop, never the whole thing. Three frameworks make it concrete: a six-layer adoption ladder, the five-step loop, and four modes of AI. Read together, they expose the one decision that separates the firms that pull ahead from the rest.
Framework 1 — The adoption ladder
The adoption ladder is the sequence of capability layers a firm climbs to use AI well, from first experiments to an AI-native business model. Maturity models vary (Gartner uses five stages, Deloitte four) but tell one story. Here's the contractor version, drawn as six layers so the two rungs that decide everything stand out: the data-readiness floor, and the AI-native ceiling almost no one reaches.
- Foundational Awareness — teams try ChatGPT, Copilot, Claude. No strategy.
- Data Readiness — the prerequisite: clean data, integrated systems, governance. Skip it and everything above is slow, expensive, and wrong.
- Productivity & Automation (AI-as-a-Tool) — writing help, document Q&A, automated reports. Most firms start here and stay: cheap wins, nothing that compounds.
- Process Reinvention (AI-in-the-Workflow) — AI inside core operations. This changes how the work is done, not just who does it.
- AI-Driven Decision-Making — models inform real calls: bid/no-bid against your win-loss history, live labor-hour estimates as the drawing set changes.
- Business Model Transformation (AI-Native) — new products and revenue built on AI. Only a low-single-digit share of firms reach it; McKinsey finds about 1% call their AI "mature."
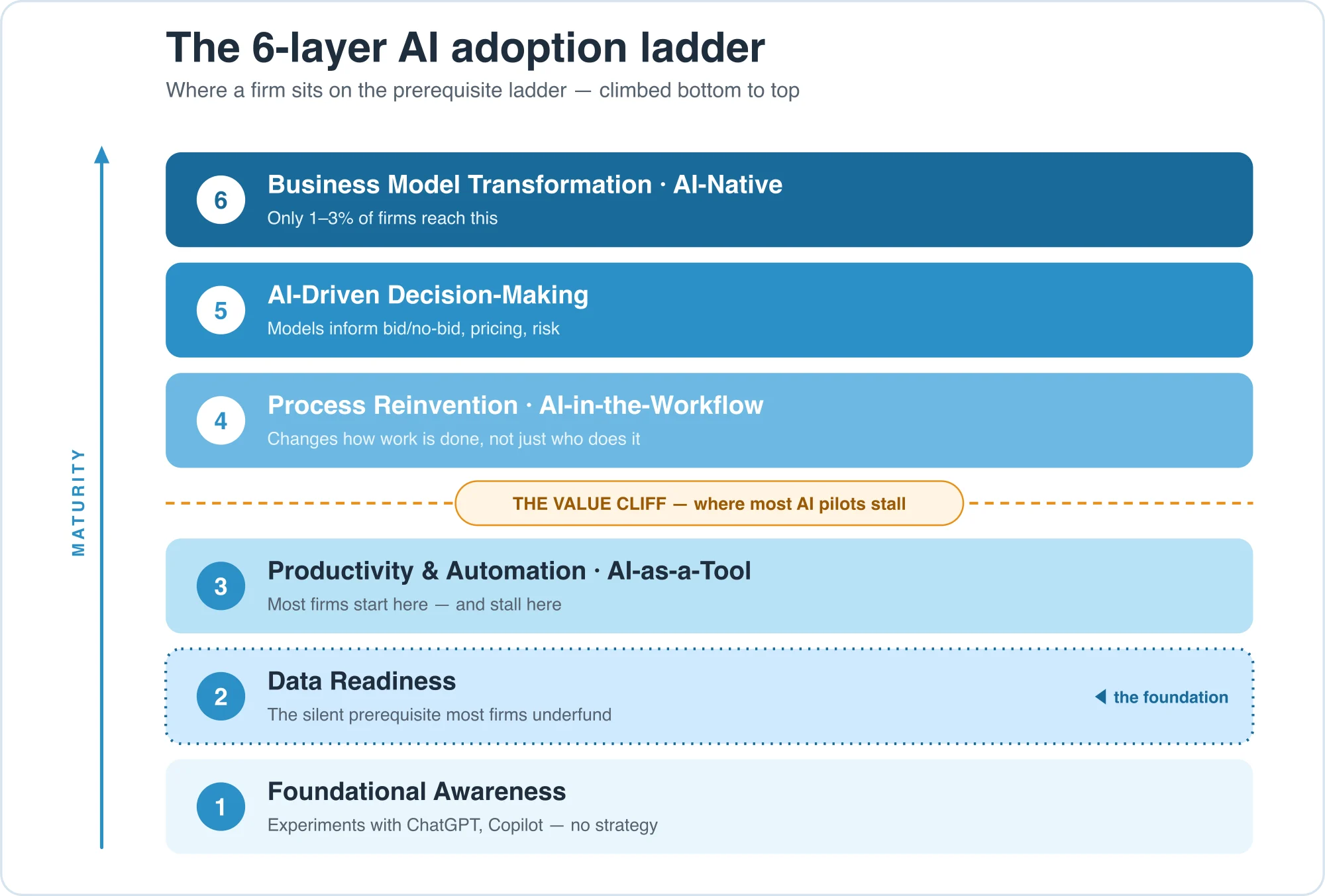
Two rungs decide the outcome. Layer 2 is the prerequisite everyone underfunds: Gartner predicts companies will abandon 60% of AI projects that aren't supported by AI-ready data, and a contractor's data is the hard kind. 70–90% of enterprise data is unstructured, and yours is the worst of it: PDFs, drawings, specs, RFI logs, scanned addenda. The work you've been treating as filing is the foundation. The cliff is between Layer 3 and Layer 4: buy a generic tool, skip the data work, and you never reach the layer where work actually changes. The pilot "succeeds," and nothing compounds.
Framework 2 — The loop
Every working AI-native system, in any industry, runs the same five-step loop. What changes from firm to firm is how many steps they own, and whether the one step that compounds runs inside their walls or someone else's.
- Data — what the system sees. Specs, drawings, RFI history, addenda, your historical exclusions, vendor catalogs.
- Policy — your judgment, written down. Bid/no-bid logic, approval thresholds, scope-gap rules: your way of working made explicit, so software can follow it.
- Tools — the actions it can take. Draft an RFI, generate a takeoff, query a vendor catalog, update Procore, file a submittal.
- QA gates — the checks before output goes live. PM review, a second pass on quantities, escalation on anything odd. What lets a person delegate without abdicating.
- Learning — the feedback that updates everything above. Revisions become policy, exceptions become rules, closed-out jobs sharpen the data. The only step that compounds.
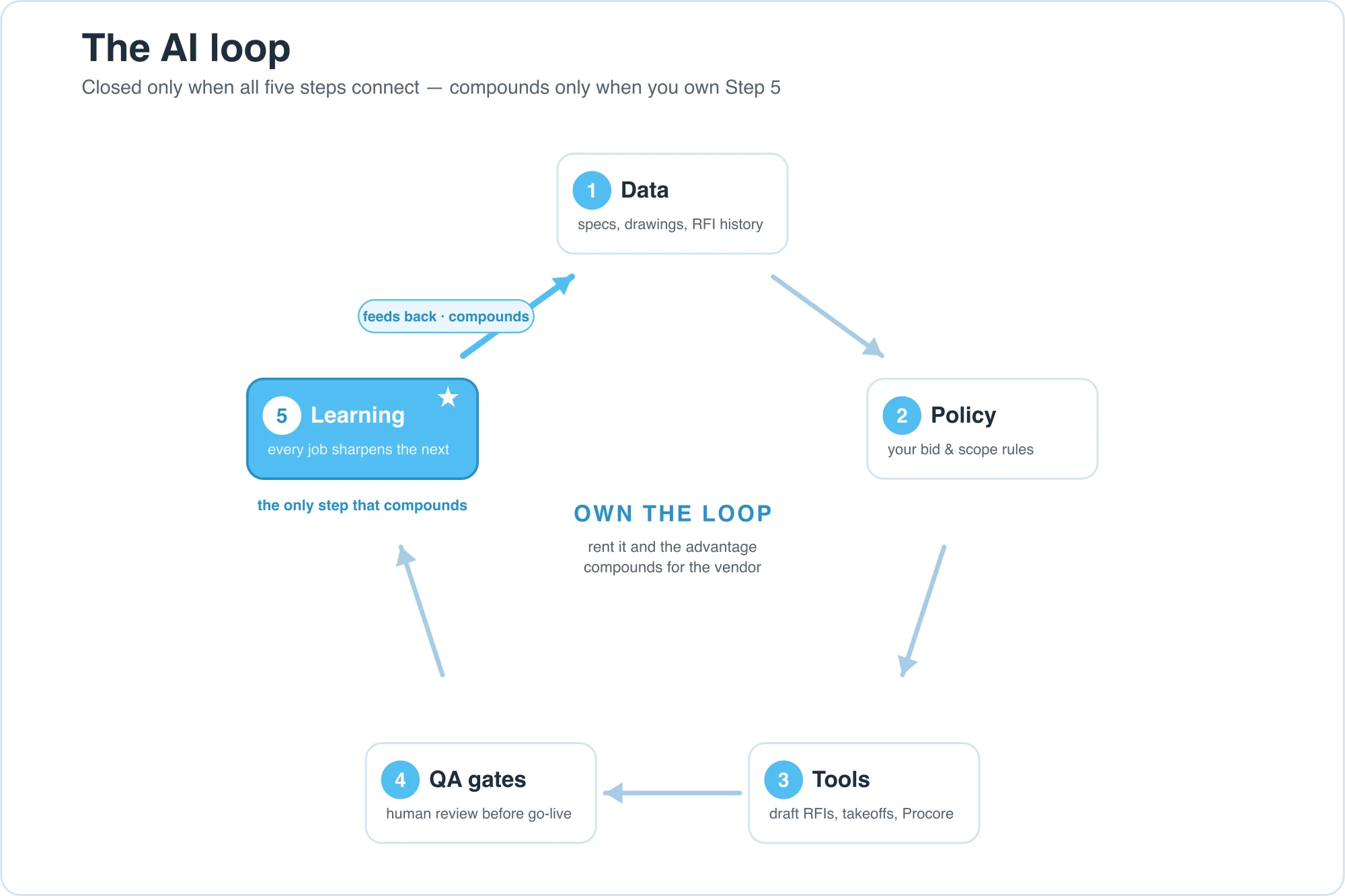
Two properties decide everything:
A loop is closed only when all five steps connect, so output from the QA gate flows back in as new input. It compounds only when the firm running it owns Step 5.
Most contractors run a fragment: some tools (Step 3), maybe a data layer (Step 1), rarely a written-down policy (Step 2) or real QA gates (Step 4). And the learning is implicit and lossy, living in a few senior heads. When the estimator who knows where the scope hides and which clauses he won't sign retires at 61, the loop walks out with him. That is the asset you are really trying to keep.
Framework 3 — The four modes
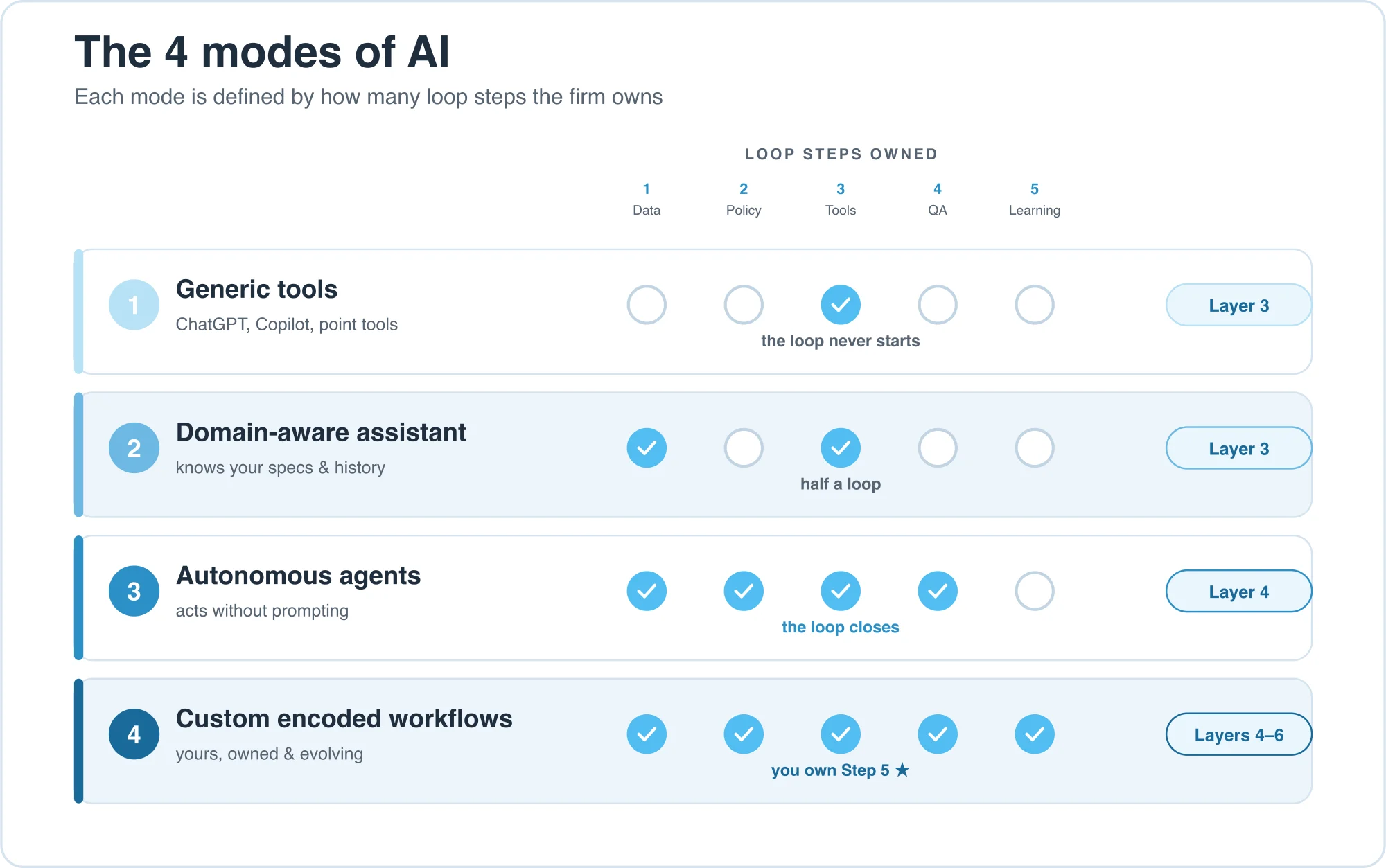
If the loop is the system, the modes are the form it takes in front of your team, each defined by which steps of the loop it actually owns.
| Mode | What it is | Loop steps it owns | Where it sits |
|---|---|---|---|
| 1 — Generic tools | ChatGPT, Copilot, generic chatbots, point tools | Step 3 only | Layer 3, without the data work |
| 2 — Domain-aware assistant | AI that knows your specs, drawings, history | Steps 1 + 3 | Layer 3, done right |
| 3 — Autonomous agents | Event-triggered workflows that act on their own | Steps 1–4 (loop closes) | Layer 4 |
| 4 — Custom encoded workflows | Your workflows, owned and evolving | Steps 1–5 (you own learning) | Layers 4–6 |
Mode 1 — Generic tools. People paste something in and get a faster email or a rough outlet count. The tool knows nothing about your specs, standards, or history; no memory, no QA but the user's own eyes, nothing that feeds back. The loop never starts. As MIT's NANDA team put it, generic chatbots "fail in critical workflows due to lack of memory and customization." Better prompting habits squeeze more out of generic tools, but they can't start the loop. This is where most firms stall.
Mode 2 — Domain-aware assistant. Now the AI knows your documents. "What spec section covers this fitting?" returns an answer with the citation. "What changed between Addendum 2 and Addendum 3?" returns a clean diff. Useful, but policy still lives in the user's head, QA is the user's own review, and learning is whatever someone remembers to write down. Half a loop; the person is still doing the work.
Mode 3 — Autonomous agents. The work runs without anyone typing prompts; this is the shift from AI tools to AI workers. An addendum monitor flags every scope change the moment a new sheet lands. An RFI agent pulls the relevant spec sections, cross-references the drawings, and has a sourced draft ready before the PM finishes their coffee. A compliance watchdog warns you 30 days before a sub's COI lapses. A person steps in for the exceptions and the judgment, not the routine. The loop closes for the first time, and your cost structure starts to separate from your competitors'.
Mode 4 — Custom encoded workflows. Your standards and know-how built into software you own and improve. Submittal review the way your PMs do it; scope-gap detection tuned to your historical exclusions; equipment schedules from your spec library. Revisions tune the policy, exceptions become rules, closed-out jobs sharpen the data, so every cycle beats the last. The only mode where the loop's output becomes your asset.
The gaps differ, which is why firms stall in different places. Mode 1 → 2 is technical: build the data layer. Mode 2 → 3 is organizational: write down your policy, set the QA rules, and trust the agent to catch what your team misses. This is where most firms stop, because closing the loop is a decision about trust, not budget. Mode 3 → 4 is strategic: own the learning step.
The trap: own the loop, or rent it
This is the decision hiding inside all three frameworks, and the most consequential one a mid-market contractor will make in the next two years. Mode 3 comes in two flavors. You can run the closed loop on your own data, in your own walls, or you can buy its output as a service from an outside vendor.
The "buy the output" path is real and growing fast: "service-as-software," priced by the outcome rather than the seat. In construction it's already here in takeoffs. A vendor like Beam AI takes your plans and your defined scope and hands back a quantified, human-QA'd takeoff in 24 to 72 hours, a finished deliverable, not a tool you operate. For work that isn't core to your firm, that's exactly right.
But run it through the loop and the trap is clear. When you rent Mode 3, all five steps are running, just not in your house. The vendor sees your data, applies their policy through their tools at their QA gate, and their model gets sharper every cycle. You get per-task productivity for the life of the contract; the vendor builds the asset.
Rent what isn't core. Own the loop for the work that defines you — your estimating logic, your scope-gap detection, your submittal review — or the advantage compounds in the vendor's direction instead of yours.
Two firms can look identical on a tools audit. One owns the learning step and gets quietly better every job. The other rents it from the same vendor its competitors use: it gets the vendor's improvements, but so does everyone else on that contract. The output improves; the edge doesn't. That gap doesn't show this quarter. It shows up as a structural margin gap a couple of years out, the kind you can't close with a hire.
Where you sit depends on your seat
Your position on these frameworks depends on the role asking. Here's the same lens, seat by seat.
- Preconstruction: Mode 2 reads the spec set and surfaces hidden scope; the loop closes when scope-gap detection is tuned to your historical exclusions, so every bid teaches the next one and win rates climb.
- Legal & risk: Mode 2 pulls every indemnification and LD clause from a 60-page subcontract in seconds; Mode 3 flags the pay-when-paid and no-damages-for-delay terms before you sign, against your standard positions.
- Operations: addendum monitors, RFI agents, and revision tracking with no spreadsheet — paying back the day a PM's correction becomes a rule the next job inherits.
- Executives: yours is the strategic call: own the loop or rent it. Portfolio visibility and contract-risk summaries are downstream of which steps you own.
- Field: the latest spec on every job site, with a citation, and the field's daily reality feeding back into the system the office runs on.
How Pelles fits — and the obvious objection
We built Pelles on one conviction: a contractor's edge is its own expertise, and that edge should compound inside the firm, not inside a vendor's model. So the platform maps onto the loop on purpose. DoubleCheck and Compare are Step 1, the data layer over your drawings, specs, and contracts, delivering Mode 2 value on day one: answers with citations, revisions diffed in seconds. Workflows encode Step 2 and Step 4 (your policy, templates, and QA gates), the move into Mode 3. Organization Agents are the part the market rarely sells: Step 5, owned by you. Senior expertise on tap, sharper every project, the move toward Mode 4.
And yes: if owning the loop is the point, why hand your data to us? Because Pelles is built to be the own-it path, not the rent-it trap. Your agents run on your data, in your own isolated environment; we don't use it to train external models, and no other customer ever sees it. The encoded knowledge stays yours. (Here's our fuller take on AI safety and data security.) And you don't have to clean fifteen years of scanned PDFs first. Making sense of the mess is the platform's job, not a prerequisite you finish before you start.
Where to start
You don't need a data team or a six-month cleanup. Pick one document-heavy workflow that hurts every week — the addendum review, the subcontract first-pass, the submittal log — and run it through a domain-aware assistant on your real files. That's Mode 2; it works on your mess as-is and pays for itself before you've committed to anything bigger. From there the frameworks point at two moves: close the loop (get to Mode 3, where few mid-market specialty contractors operate today, which is exactly why it's where the separation happens), and own the learning step for the work that defines you.
Start both this year and you spend the next one pulling ahead. Put it off, and you spend 2028 discovering that some gaps don't close with a hire.
If you want to see what closing the loop looks like on your documents and your workflows, explore Pelles Core or book a working session with our team. Bring a real bid set or a live contract — the conversation is a lot sharper when it's your data on the table.
Frequently asked questions
What is an AI-native contractor?
An AI-native contractor is a firm that runs a closed, compounding loop over its own information — data, encoded policy, tools, QA gates, and learning — rather than a firm that simply uses AI tools. The defining trait isn't how many AI products you've bought; it's whether the learning step (where every project makes the next one sharper) runs inside your firm, on your data, so the advantage accumulates as your asset instead of a vendor's.
Why do most construction AI pilots fail to deliver value?
Two reasons. First, firms skip the data-readiness work: 70–90% of enterprise data is unstructured (PDFs, drawings, specs, RFI logs, scanned addenda), and Gartner predicts companies will abandon 60% of AI projects that aren't supported by AI-ready data. Second, they deploy generic tools that accelerate individual tasks but never change how work is done. MIT's NANDA initiative found that 95% of enterprise GenAI efforts produced no measurable P&L impact: the gains don't compound because the loop never closes.
Should a contractor build AI in-house or buy it as a service?
Both have a place; the question is which work is core. Buying AI output as a service (service-as-software) is fast and appropriate for non-core work. But when you rent the output for work that defines your firm — estimating logic, scope-gap detection, submittal review — the vendor's model gets sharper every cycle, not yours. The rule of thumb: rent the work that isn't core to your identity, and own the loop for the work that is.
What's the difference between an AI assistant and an AI agent in construction?
An assistant (or copilot) answers questions and drafts outputs grounded in your documents, but a person still drives every step; it's half a loop. An agent acts continuously without prompting: an addendum monitor flags every change the moment a new sheet lands, and an RFI agent has a sourced draft waiting before the PM finishes their coffee. With an agent the workflow runs itself and the human steps in for exceptions and judgment, which is the point where AI moves from assisting to actually doing the work.
How should a construction company start adopting AI?
Start with one document-heavy workflow that hurts every week — addendum review, subcontract first-pass, or submittal logs — and run it through a domain-aware AI assistant on your real files. It works on messy, unstructured documents as-is, so there's no six-month data cleanup first. Once it proves out, close the loop: add your policies and QA gates so the workflow runs semi-autonomously, then own the learning step so every project sharpens the next.
What is the AI maturity model for contractors?
It's a six-layer ladder a firm climbs to use AI well: (1) Foundational Awareness, (2) Data Readiness, (3) Productivity & Automation, (4) Process Reinvention, (5) AI-Driven Decision-Making, and (6) Business Model Transformation. The two rungs that decide outcomes are Layer 2, data readiness, which most firms underfund, and the jump from Layer 3 to Layer 4, where AI starts changing how work is done instead of just speeding up tasks.